



No, I am not saying that neural networks can achieve everything. The endless possibilities I am facing do not extend outwards towards practical goals. Instead, when I am experimenting with applications of neural network for creative and original art, I am overwhelmed by the endless options and variations at my disposal. Even if I stick to a single pre-trained neural network, there is the choice of the content and style images, content and style weights, different optimizers with their parameters and last, but not least, selecting which network layers are used to control content and style generation. In addition, the absolute values of content and style weights do matter, so that 10 and 1000 give different results than 100 and 10000. And the right values for each case are different, depending on the material and image sizes.
Then there is a choice of several pre-trained networks. I have already touched here one alternative, nin-imagenet-conv, to replace the default, VGG19. The latter seems to produce sharper quality and follow the style of the model image more faithfully, so it appears to be the favorite of most who experiment with neural-style. For me, looking for a practical tool for original work, nin-imagenet-conv, which works well with much smaller memory, feels almost fully adequate.
I made some tests, using this drawing as a style model.

Running a photo through both VGG19 and nin-imagenet-conv, with this style model, gives, respectively. This illustrates well how a neural network does not simply modify an image; it actually builds its own understanding of the image contents and then recreates it. VGG19 has visualized hair where nin-image-net sees hair and shoulder differently. Nin-imagenet-conv, then, has perhaps visualized the face more accurately.


Next, I tested VGG_FACE, a neural network pre-trained to recognize faces and facial features. Now something interesting happens. The network first faintly sees the contours of the lady, but then loses the view. Yet the lines that develop later (on the right) seem to belong to a human body even if no human image emerges.
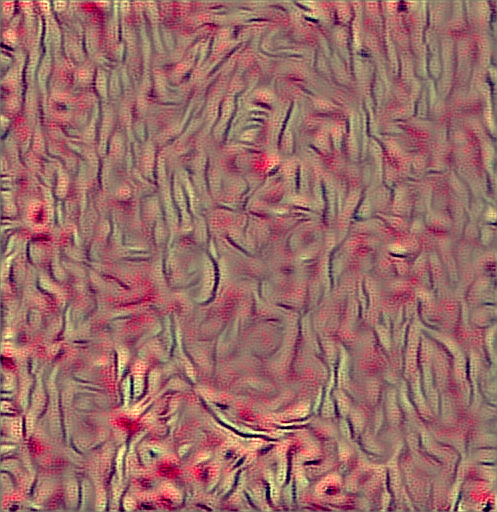

A second try, changing the parameters, leads to something similar. There is something reminiscent of a human face, but still no face. A further trial, with increased content weight finally produces a drawing-like picture of a face, but in an interestingly distorted form (right).


Also the earlier iterations that produced the image on the right above are interesting. We can see how the final image is being formed.


Increasing content weight leads to a more realistic image, but only after a number of intermediate stages. Here, once again, an earlier version feels more interesting to me. And looking at the final result, once again it can be noted how the neural network has had difficulty in perceiving the hair and the contours of the shoulder.



So far I have been writing about using pre-trained neural networks only. But it is also possible to train neural networks oneself, with the kind of images and features one wants them to be able to recognize. I have already been dabbling at this, but so far I have only experienced that while almost any network can produce some kind of interesting effect, it is not easy to train a network to be a well-behaving tool. Still, I strongly feel that in the long run, for original artistic work, training one’s own neural network is the way to go. Yet at the same time it is not something to be achieved quickly or easily. At least at this phase, the number of possibilities really becomes endless.