



Pix2pix is a brand-new tool which is intended to allow application-independent training of any kind of image transform. All that is needed is a dataset containing image pairs, A and B, and one can train a network to transform to either direction. Possible applications include colorization, segmentation, line drawing to image, map to satellite view, stylization and so on. The operations work in both directions, so with a properly trained network one can generate a plausible satellite view from a map, or a building facade from a colored segmentation. Check the link above or the paper on the method for more information.

I made a first quick test using Graz02 dataset, consisting of city views with people and corresponding images with human silhouttes on white background, and then had a look how Pix2pix will construct a full view from a mere silhouette. The dataset was very small, so I did certainly not believe spectacular performance. I was just looking for something interesting. Understandably, the model did not perform well on a silhoutte which was not part of the training set. It produced a human shape with a background which did not change much when run with different input images.
But the results obtained using silhouttes from the training set were quite interesting, from an artistic point of view.
My next test was made using my own dataset of 2500+ photos, mainly landscapes. I produced image pairs in which the input image was a center crop of the target image, and tried to train the model to guess what should be outside of what it sees. Again, a very hard task for a model, given a small dataset with quite varying views. But I was looking something interesting, not magic.


It turned out quite interesting. I have earlier experimented with GANs trying to create imaginary landscapes based on the same set of photos, but never could get the model trained to produce higher than 128px images. Now I got amazing imaginary landscapes in 512×512 px without any problems.
The only disturbing thing in these images is a roughly square area in the middle, which differs from the rest of the image and has higher frequency content. I don’t know as yet where it comes from. It could result from the task: to reduce the input picture into the middle of the canvas and then fill the rest with something that fits with it. But if this is the case, then one would expect the “watermark” be roughly 256×256 px, but it is much smaller.
Reading the paper, pix2pix appears to use a technique that the discriminator is not looking at the whole picture to determine whether it is real or fake, but only a smaller patch. Could this be the reason of the high resolution “watermark” in the middle? That the generator has learned to put a higher quality patch exactly where the generator is looking at? I am currently running a test so see what happens if the discriminator is not using this patch technique.
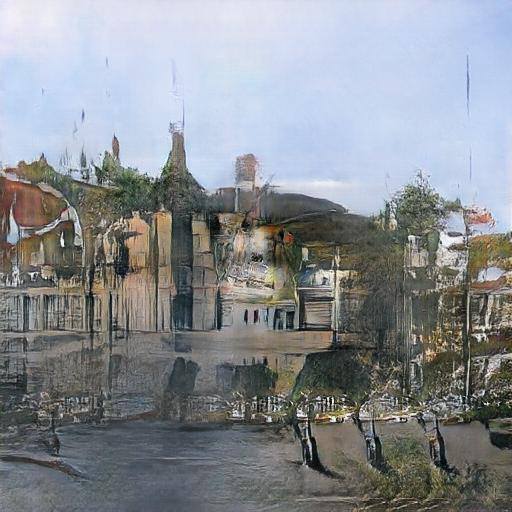

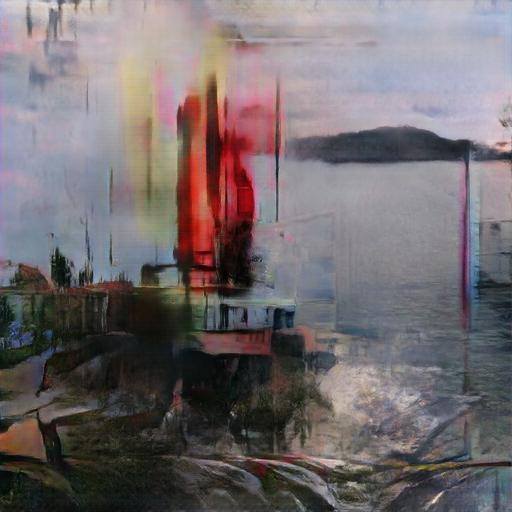
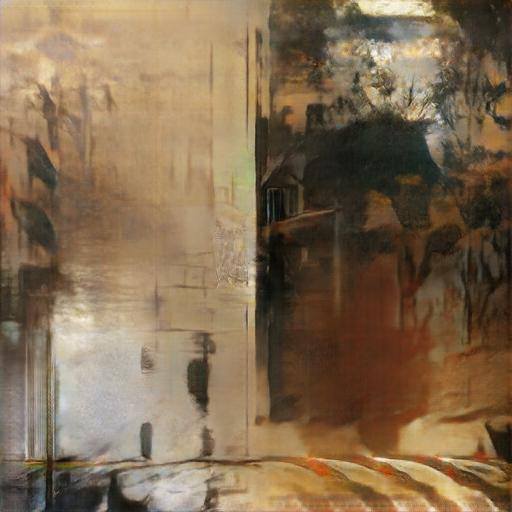










Looks cool 🙂 Could you try to mix galaxy pictures with something?
Pingback: Seeing beoynd the edges of the image | Erratic Explorations
Very interesting results. Your pictures are 512, is this a memory limitation?
I am assuming you are using a graphics card. What is your memory on the card?
I am using a GTX1070 with 8 GB memory. With pix2pix I didn’t try to go beyond 512, but with the recent BicycleGAN I was able to train a network for 1024px, even if the training becomes quite slow, both because of the increased model size and reducing the batch size to minimum. Also the model complexity counts… with fewer layers one might be able work with a larger image.
Hi Can you share the code to use pix2pix with 512×512 images ? Thank you
Unfortunately I don’t have a complete working code for this any more as I was then continuously modifying the code with different experiments. In principle the modification to 512px is simple, just add another conv layer on the input side and a deconv layer on the output side. Today, a pytorch implementation might be a better choice though. I have seen pytorch code where you just give the number of conv layers as a parameter, so that adding layers to go from 256 to 512 simply requires changing a parameter value.