It is now six years since I started working on images using neural networks and deep learning. In this series I will present an overview of this adventure, six years and ongoing, touching on the techniques used, showing samples what could be made back then, relating the development of field in general and my own work in particular.
In summer 2015 I was interested in processing photographs drastically, reducing them to bare essentials if possible, using libraries such as Processing and OpenCV. I could not, however, get as far as I would have liked, so I started looking for more powerful techniques.
I was lucky. Exactly then two new techniques had been released, both using neural networks and deep learning: Google’s Deep dream, which did not appeal to me aesthetically, and neural-style which was claimed to be able to separate between the content and the style of an image, and thus transfer the style of one image into another.
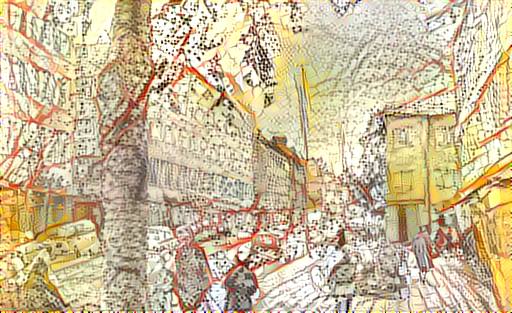
And so it could, indeed. I tried the technique by taking the style of a gouache painting by a friend of mine, Kivi Larmola, of a street in a small French town, and applying it to another street view, a photo I had taken in Cluj-Napoca, Romania. The result was met with so much interest that I started a Facebook group on neural network based image processing. Instead of being a general discussion group, it soon in practice became a virtual window into my studio, as posted frequently on my work and methods, showing results and also reporting of the developments in the field at large. I have continued with this all these years.

Next thing I did was to take a photo from Sarvikallio in Tuusula, Finland, in itself a quite Finnish landscape, and try to apply styles from six paintings by different artists to it. The result was a strange experience. I was totally aware that the algorithm did not at all understand the style of these artists in general, it only applied color and textures extracted from their specific paintings to my photo.
Still, it felt as if these artists, Axel Gallén-Kallela, Konrad Mägi, Hugo Simberg, Isaak Levitan, Hjalmar Munsterhjelm and Edvard Munch, would have painted exactly the same view. The illusion was, and still is, baffling.
I have elsewhere written about how neural-style works. Roughly speaking, a pretrained image classification network is used to filter different features from an image, layer by layer from simpler to more complex things, first color, then things like lines and finally complex combinations of these, such as eyes or windows. Based on measuring these features, it is possible to perceive and even to reconstruct the contents of an image. Even more interesting is how a rather simple mathematical technique could be used to evaluate how these features appear in combination, which turned out to be useful as an evaluation of style (in the sense of how color and texture are used in this particular image).
There were quite a many tunable parameters in the algorithm, such as which layers exactly are used for control, and to what degree. This made possible a degree of control on, for instance, what kind of features were prominent in the output image. I tested these options even to the extremes, like in the following video which shows a single photo from Kaivopuisto, Helsinki, Finland, transformed in various ways.
It did not take long before I started to make my own modifications to the code. It took longer, however to master it, grasp the totally new way of working with images, but I started from smaller modifications until I knew the code inside out, used it as a basis for various experiments, and even helped other to understand and modify the code.
Simultaneously, people in my FB group came up with ideas to try. It was already possible to proceed with multiple style models, but what about an image whose content would match two different images? I made changes to the code and we tried. On the left, our dog is looking two ways, on the right, faces of both me and my wife.


There were also discussions what would happen if we tried make an image which is not like this image, either in content or in style. At this point I was already familiar with the algorithm, and skeptical about the results. It has more meaning to optimise towards similarity than away from it. In the first case, there is a definite goal, in the second the goal is practically anything.
Yet, technically it was doable and so we tried, using a photo of a village in Greenland.
Interestingly, such negative goals have recently surfaced within text based image synthesis: image creation is steered towards something, simultaneously avoiding something else. The principle is the same, and works as long there is a positive goal also. You have an objective function consisting of multiple parts. Merely avoiding a goal, however, seldom leads anywhere.



All in all, neural-style was great and, to a degree, still is. Even if a much better known colleague once said that neural-style could not achieve much else than painterly swirlies. I still suspect that he might not have tried enough. I had started half a year earlier, and there was not much else to use at the time. Spent a fall, winter and spring with neural-style. Didn’t even have a GPU, processing one image took typically an hour, which was totally ok. I could monitor the progress and interrupt it if needed. Go away and come to check at times on the progress.
As a final example of this part, a view from the town where I spent my youth and a picture of myself, in a style borrowed from a topographical map