



Kun kuvallinen tekoäly muuttui 2022, kyse ei ollut niinkään tekstimuotoisen ohjauksen yleistymisestä, vaan siitä että siirryttiin monoliittisiin malleihin, joiden kyvyt saattoivat olla paljon aiempia laajemmat… olihan ne koulutettu aiempaan verrattuna valtavalla koulutusaineistolla. Samalla kuitenkin esimerkiksi tekstiohjaus integroitiin jo koulutusvaiheessa osaksi mallia, jonka toiminnallisuutta ei voinut ulkopuolelta säätää niinkuin alalla oli aiemmin tehty.
Ensimmäiset tekstiohjatut kuvasynteesit nimittäin toimivat näin. Meillä on kuvageneraattori, joka on koulutettu rajallisella kuva-aineistolla, jonka pohjalta se pystyy tuottamaan kuvia ja kuvaa voidaan ohjata ulkopuolelta sen syntyessä. Kuvageneraattorin ei tarvitse osata tehdä valmiita kuvia, koska lopullinen kuva syntyy ulkopuolelta tulevan ohjauksen avulla.
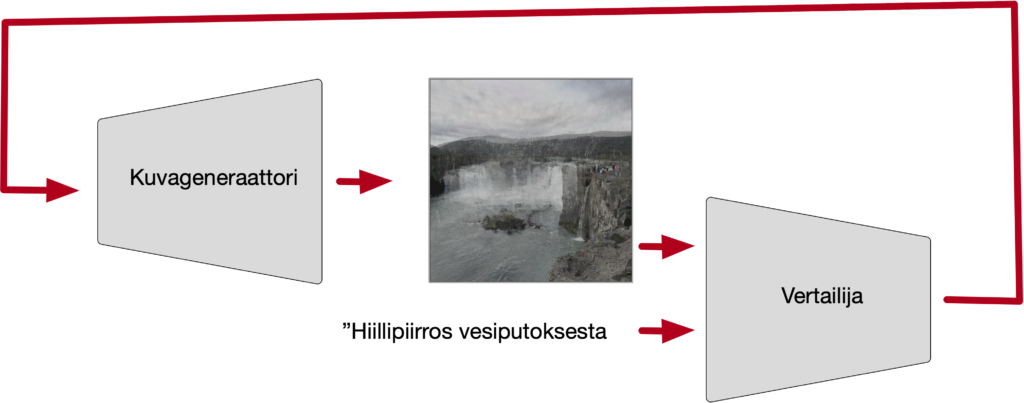
Kun Joel Simon artikkelissaan ”Beyond Slop” kirjoittaa ”In the original CLIP+VQGAN work, you could optimize toward any loss you wanted, not just text similarity. Loss functions aren’t bounded by datasets the way latent spaces are. They’re a different kind of creative material entirely.” hän puhuu juuri tästä. Kun kuvan syntyä ohjataan ulkopuolelta, meillä on täysi vapaus kehitellä vaikka millaisia keinoja vaikuttaa kuvan syntyyn. Se mitä kuvaa tekevä malli itsessään osaa, millä kuvilla se on koulutettu, on vain visuaalista aineistoa josta ohjauksen avulla voidaan edetä johonkin aivan muuhun. Kuvageneraattorin olemus ei kuitenkaan ole samantekevä, käytännössä huomaa hyvin äkkiä että lopputulos on erofunktion (vertailija) ja kuvageneraattorin yhteistoiminnan tulos. Ratkaisevaa on että ne toimivat hyvin yhteen.
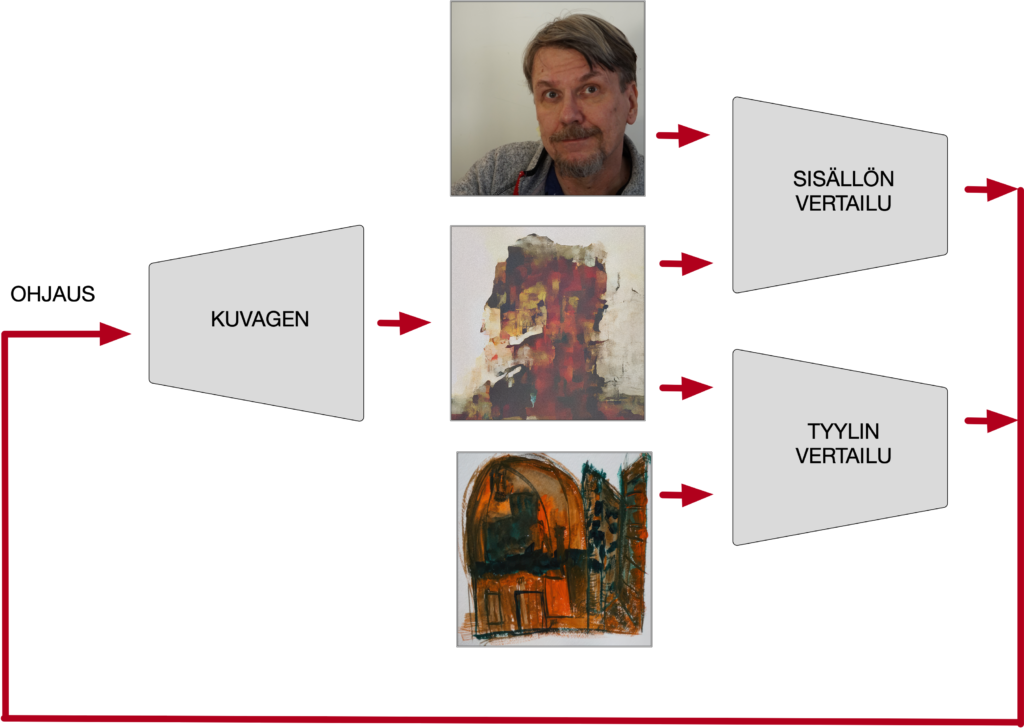
Ensimmäinen tekoälypohjainen kuvantyöstötekniikka, tyylimuunnos, jota lähdin kokeilemaan 2015, toimii samalla tavoin. Nyt vain syntyvää kuvaa verrataan kahteen kuvaan, joista toisesta halutaan ottaa kuvan sisältö ja toisesta tekstuurin ja värin käyttö. Tyylimuunnoksessa ei edes tarvittu erityistä kuvageneraattoria, vaan ohjattiin pikselikuvaa ihan sellaisenaan.
Sanotaan se vielä ihan selvästi. Tekoälyjättien kouluttamat mallit voivat olla kuinka upeita hyvänsä, mutta ne ovat juuri vain sitä mihin ne on tehty. Stable Diffusion oli ensimmäisiä jotka menivät tälle linjalle… kuvaa tekevä malli sisälsi tekstiohjauksen, eikä sitä voinut oikein käyttää kuvapromptilla ohjattuna. Siihen tarvittiin toinen, kokonaan uusi eri aineistolla (kuvat vs kuvapromptit) koulutettu malli. Ulkopuolinen ohjaus oli periaatteessa mahdollista, mutta mallien raskauden ja muistitarpeen takia käytännössä vaikeata.
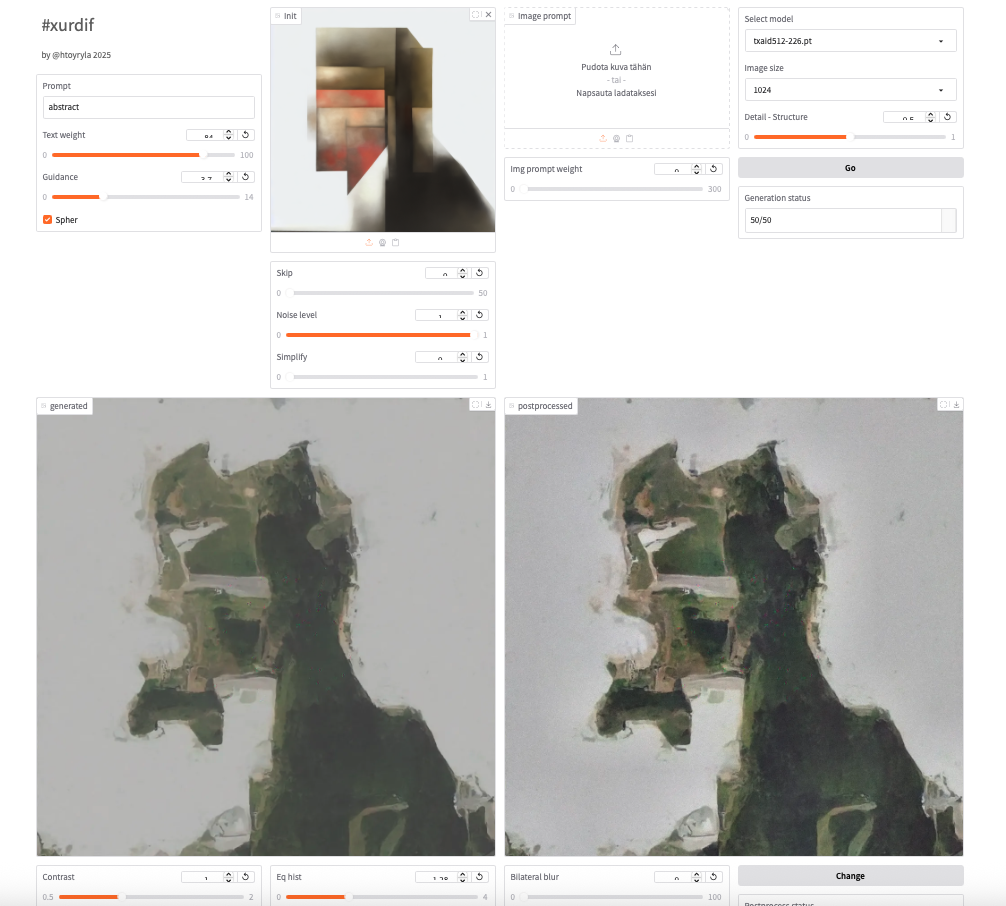
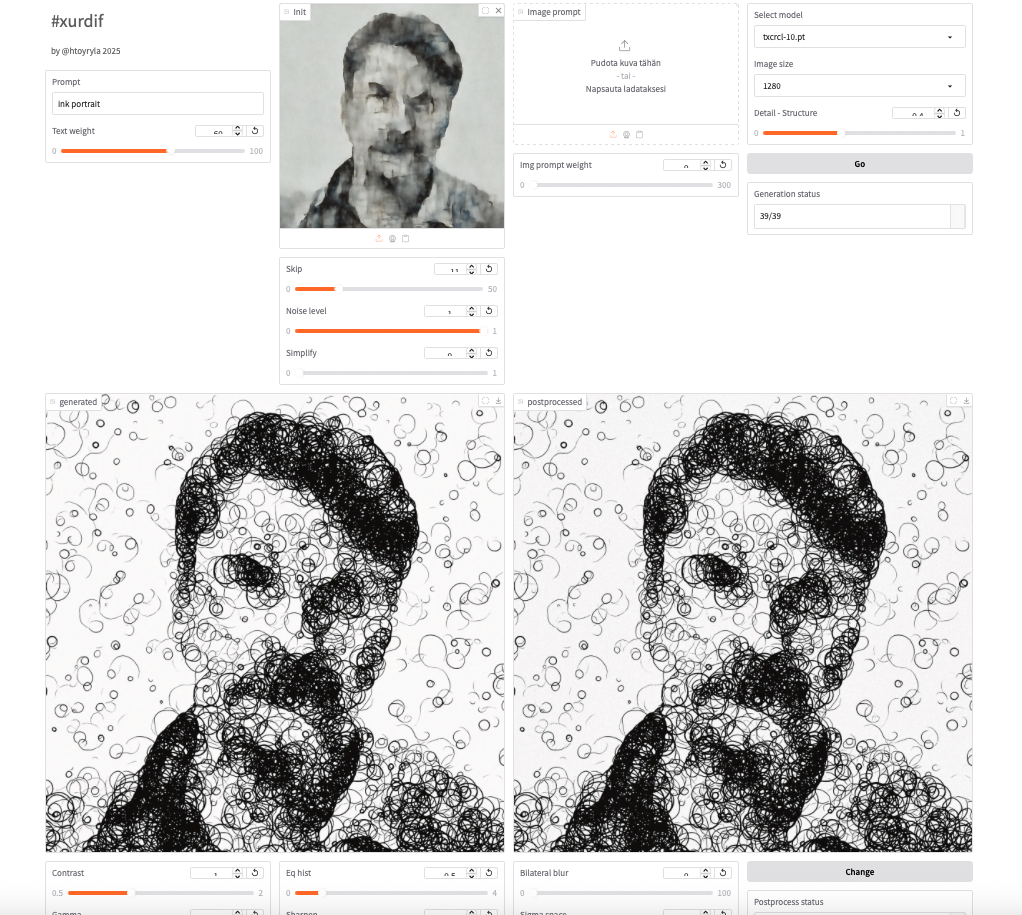
Kumpi tie kenellekin sopii on aivan kiinni omista tarpeista. Itse en ole lähtenyt seuraamaan kuvallisen tekoälyn valtavirtaa Stable Diffusionin jälkeen, vaan enemmänkin palannut aiempaan toimintatapaan. Seurannut kyllä tekniikan kehitystä silloin kun jotakin sopivaa uutta on ilmaantunut. Kehitellyt uusia, parempia työkaluja. Diffuusio on selvästi parempi kuvangenerointimenetelmä kuin esim. GAN, ja jo vuosia olen kehitellyt omaa kevyttä diffuusiotekniikkaani. Keskeisenä ideana on, että diffuusiomallit ovat kevyitä, ja ne koulutetaan nopeasti pienehköllä kuvasetillä. Kullakin mallilla on silloin oma luonteensa, oma rajallinen ilmaisunsa. Malleja voi nopeimmillaan kouluttaa puolessa tunnissa, eikä tässä ole kyse aiemmin koulutetun mallin hienosäädöstä vaan kokonaan tyhjästä koulutetusta uudesta mallista. Tällöin malli voi jo itsessään toimia tietynlaisena tyylinä tai siveltimenä…toisaalta on myös mahdollista kouluttaa joustavampia, monikäyttöisiä malleja.
Alla ylinnä käytössä satelliittikuvilla koulutettu malli, sen alapuolella pienillä mustilla renkailla koulutettu malli.
Tällaisen tekniikan kanssa työskentelyssä on hienoa, kun voi kerran toisensa jälkeen kehitellä uusia ideoita ja toteuttaa ne. Itseäni kiinnostaa nimenomaan kuvallisen lähtöaineiston kanssa työskentely… suurin osa kehittämistäni työkaluista on tavallaan kuvamiksereitä, jossa kahden tai useamman lähtökuvan pohjalta luodaan uutta kuvaa. Jo se 2015 tyylimuunnos oli tällainen tekniikka. Hyvin samantapainen on myös MRF-kuvamiksaus, jollaista alkujaan käytin jo 2016.
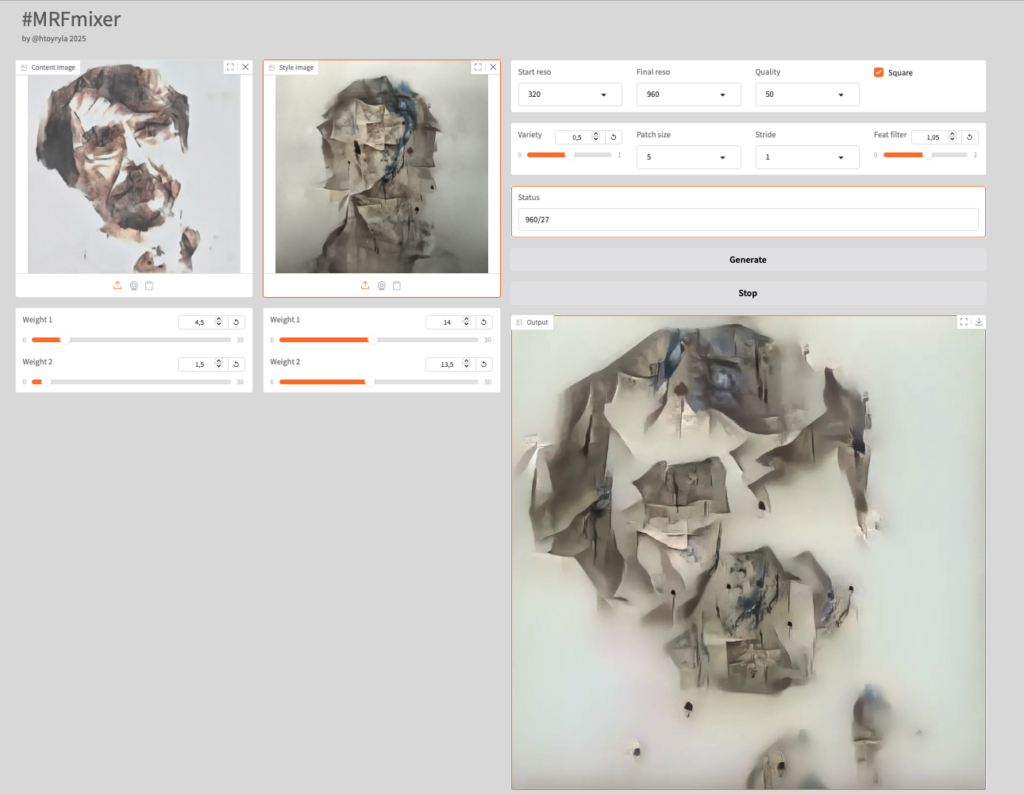
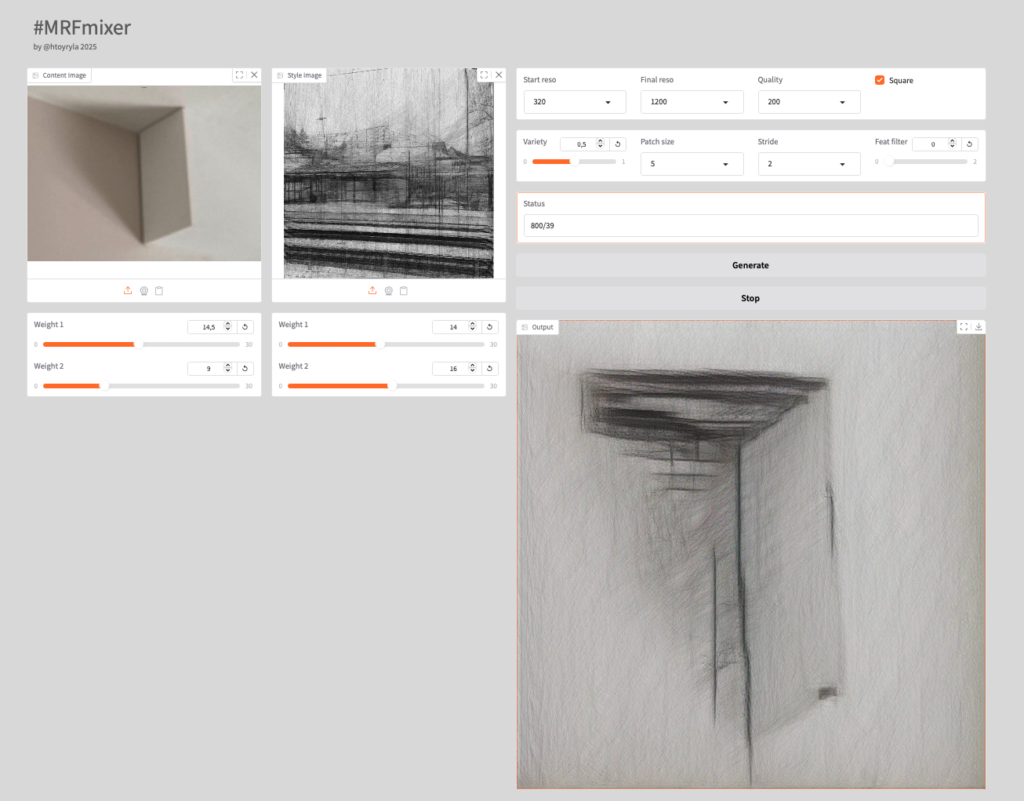
Koska tekniikat ovat modulaarisia ja toteutus itse kehittämäni, voin uusien ideoiden myötä yhdistellä ja kehitellä niitä eteenpäin.
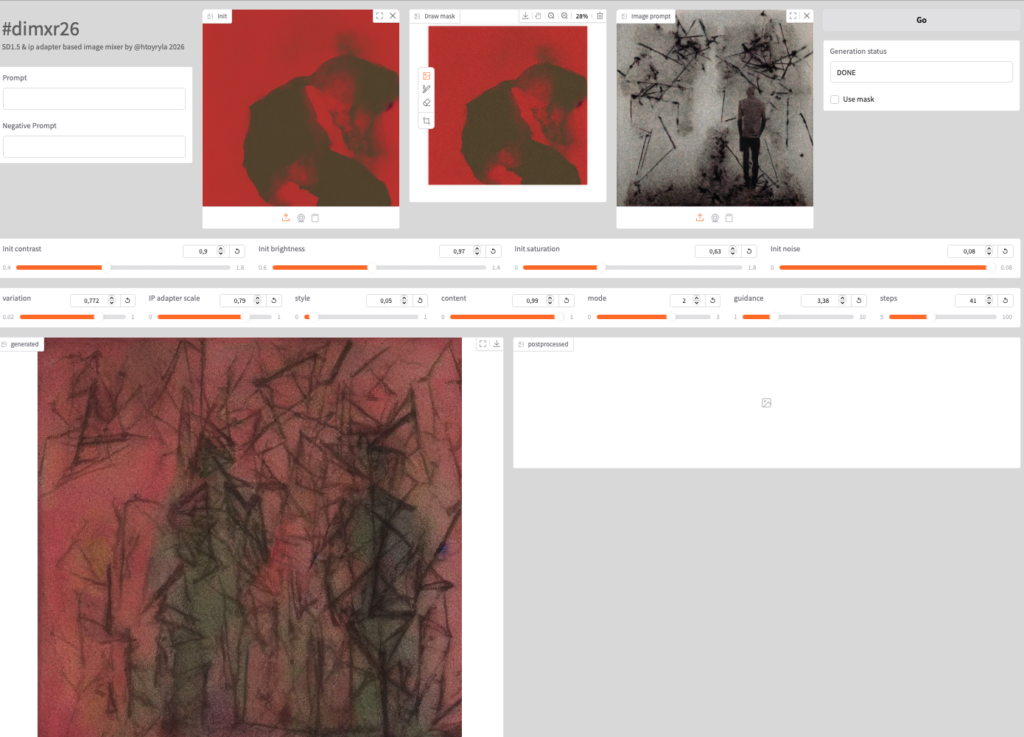
Katsotaan vertailun vuoksi miten Stable Diffusion -pohjainen kuvamikseri käyttäytyy. Koska SD on koulutettu tekstiohjauksella, sitä ei kovin hyvin voi suoraan ohjata kuvapromptilla, mutta IP-adapterin kanssa sitä voi kokeilla.
Kyllähän se toimii ja tulokset voivat näyttää hienoiltakin, mutta enimmäkseen omasta kuvallisesta ilmaisusta kiinnostuneelle jää olo, että mistä tuo tuli, en minä sitä tehnyt. Hyppy lähtömateriaaleista lopputulokseen on liian suuri.
Kytkös ei ole suoraan visuaalinen kuten ylempänä esittelemissäni menetelmissä, vaan kuvaprompti tulkitaan käsitteiksi, joiden mukaan uusi kuva luodaan. Usein käy niinkin, että malli näkee vähemmän esittävässä kuvassa jotakin aivan muuta kuin mitä ihminen siinä näkee.
Kirjoitus on toinen osa sarjassa ”Tekoälytaide aivan toisin”. Ensimmäinen osa Tekoälytaide ennen tekoälyä .
Kirjoituksessa mainittu oma diffuusiototeutus löytyy täältä https://github.com/htoyryla/xurdif
ja tyylimuunnoksen moderni oma toteutus täältä https://github.com/htoyryla/stylemixer .