



Kirjassani käsittelin yhden luvun verran (s. 99- 101) uutta tekniikkaa, diffuusiota, jossa kuva pannaan kasvamaan kohinasta. Pidin sitä selvästi kiinnostavana taiteelliseenkin työhön ja tein sillä joitakin kokeiluja. Diffuusiotekniikka on sen jälkeen kehittynyt monella tavoin ja sen pohjalta on syntynyt useita palveluita, jotka ovat nostaneet tekoälypohjaisen kuvanteon ensimmäistä kertaa todella laajan yleisön tietoon ja käyttöön. Siksi näen nyt tarpeelliseksi päivittää kirjani tällä ylimääräisellä luvulla, jossa käsittelen tarkemmin diffuusion tekniikkaa, sen sovelluksia sekä vaikutuksia kuvanteon maailmassa.
Niinkuin niin monen muunkin jo käsittelemämme tekniikan, myös diffuusion idea on periaatteena yksinkertainen mutta nerokas. On helppoa peittää kuva kohinaan, jopa niin ettei mitään kuvaa ole enää nähtävissä. Tekoälyn avulla voimme kääntää tämän prosessin, opettaa esimerkkien avulla neuroverkon poistamaan kuvasta kohinaa. Äärimmilleen vietynä voidaan pelkästä kohinastakin synnyttää kuvia, ja juuri niin diffuusio toimii.
Alla olevassa esimerkissä lisäämme kuvaan vaihe kerrallaan hieman kohinaa, kunnes lopulta kuvasta ei ole mitään jäljellä. Esimerkki on yksinkertaistettu. Käytännössä kohinaa lisätään hyvin pienin askelin, tyypillisesti tuhat kertaa, joten kerrallaan tehtävä muutos on hyvin pieni.

Kun sitten koulutamme neuroverkon arvioimaan kuinka paljon kuvassa on yhdellä kertaa lisättyä kohinaa, ja käytämme sitä kohinan poistamiseen toistamalla yksittäinen operaatio tuhat kertaa, pääsemme puhtaasta kohinasta takaisin kuvaan. Jos kohinaan peitetyn kuvan sijaan lähdemme satunnaisesta kohinasta, voimme päästä mitä erilaisimpiin kuviin, ja myös ohjata diffuusiota kohti haluamaamme tavoitetta, kuten olemme kautta kirjan eri tavoin jo tehneet. Tällä hetkellä toki suosituin malli on ohjata kuvan syntyä tekstimuotoisen kuvauksen perusteella (kirja s. 87 – 89).
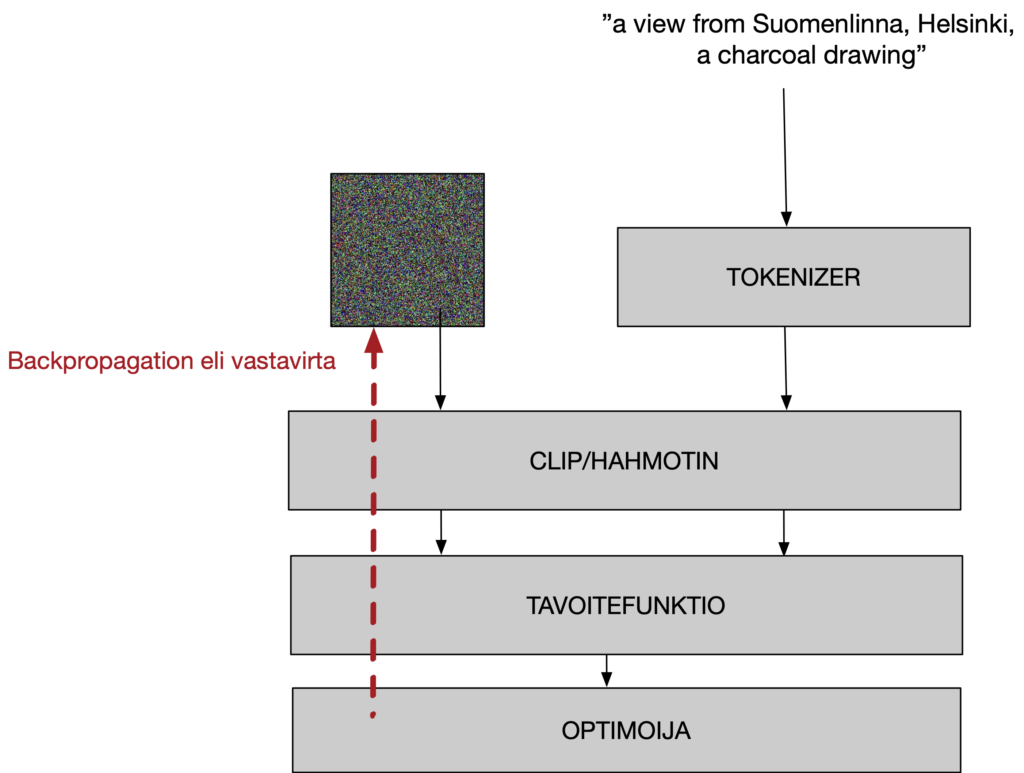
Tekstiohjauksessa kehittymässä olevaa kuvaa verrataan joka vaiheessa annettuun tekstiin, ja kuvaa ohjataan aavistuksen verran tekstin määräämään suuntaan. Tämän mahdollistaa CLIP, joka muuntaa sekä kuvan että tekstin enkoodattuun muotoon, jossa niitä voidaan verrata toisiinsa.
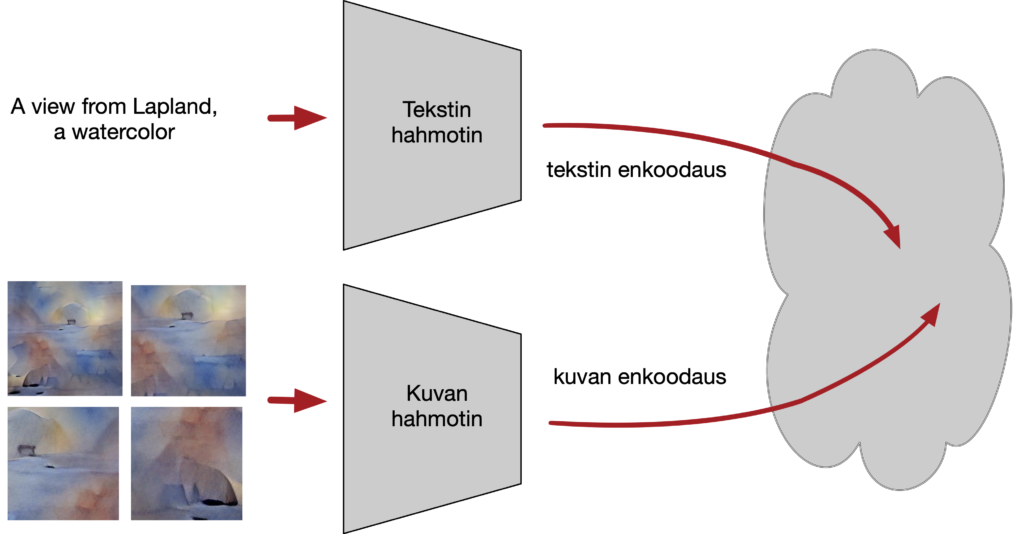
Tämä selittää periaatetasolla sen, miten kuvaa ylipäänsä voidaan synnyttää tekstikuvauksen pohjalta. Kuvan ei tarvitse syntyä diffuusiolla, mutta käytännössä se on osoittautunut kohtalaisen ylivoimaiseksi verrattuna aiemmin käytettyihin menetelmiin (VQGAN, kirjan s. 81 – 84, muita tapoja s. 92 – 97).
Kuvasta kuvaksi diffuusiolla
Omassa työskentelyssäni haluan käyttää omaa kuva-aineistoani lähtökohtana ja siksi harvemmin käytän pelkkää tekstipohjaista synteesiä. Kirjani kokeiluissa (s. 100) totesin, ettei diffuusiota voi alustaa omalla lähtökuvalla, joten jouduin sen sijaan ohjaamaan syntyvää kuvaa kohti antamaani kuvaa. Myöhemmin on selvinnyt sekin, miten diffuusio alustetaan lähtökuvalla.

Ongelmana oli diffuusion perusluonne: kuvan synty lähtee kohinasta. Kun tällaiseen prosessiin syötti aloituskuvan, kohina peitti sen niin ettei lähtökuvalla ollut mitään vaikutusta. Tähän oli kuitenkin yksinkertainen ratkaisu. Kun lähdetään tietystä kuvasta, lisätään siihen sopivasti vähemmän kohinaa, ja vastaavasti kohinanpoistovaiheita vähennetään. Hyppäämme jo osittain kohinasta puhdistetun kuvan kanssa ikäänkuin keskelle kohinanpoistoprosessia. Säätämällä lähtökuvan ja kohinan suhdetta ja vastaavasti tarvittavien kohinanpoistokierrosten määrää, voimme myös säätää alkukuvan ja tekstiohjauksen välistä tasapainoa.

Diffuusion muunnelmia
Perusmuodossaan diffuusiossa kuva syntyy pikselikuvana jopa tuhannen vaiheen kautta, mikä on hidasta ja kuvakoon kasvaessa myös paljon muistia kuluttavaa. Prosessin nopeuttamiseen löytyy helpohko keino: kun on arvioitu poistettava kohina tietyssä vaiheessa, pystytään matemaattisesti arvioimaan kohtalaisen hyvin paljonko kohinaa esimerkiksi 20 vaiheen jälkeen pitää poistaa. Näin kuva voidaan synnyttää 50 kierroksella tuhannen sijaan.
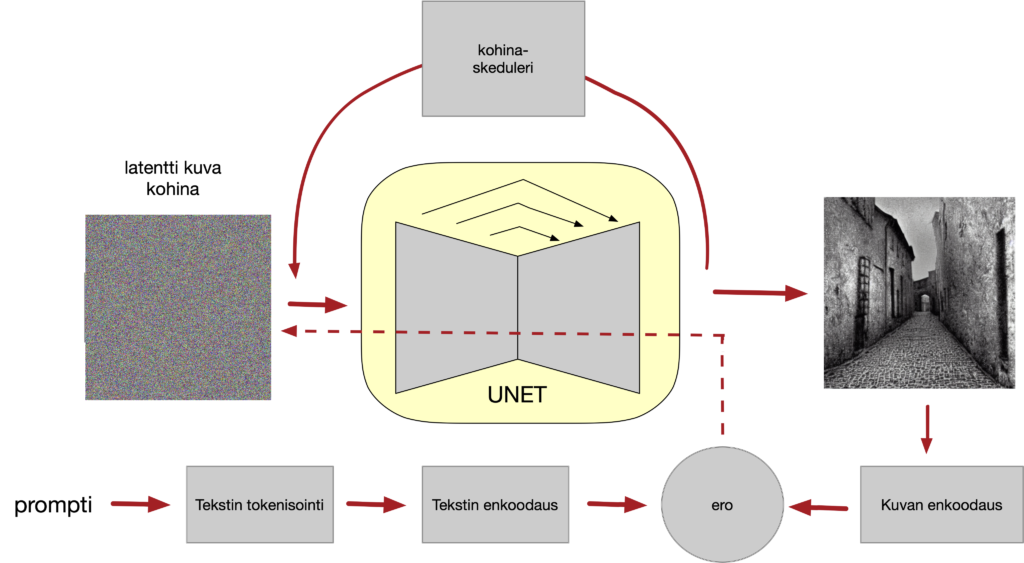
Diffuusion toiminta voidaan nyt kuvata ylläolevalla kaaviolla. Lähdetään joko kohinasta tai lähtökuvasta, johon on lisätty sopivasti kohinaa. Kohinan poistamiseen käytetään U-net -tyyppistä neuroverkkoa, joka soveltuu kuvan muuntamiseen ja jollaista käytimme jo kirjan luvussa Kuvaa muuntava yleiskone (s. 41 – 54). Tässä U-net on koulutettu poistamaan kuvasta aavistuksen verran kohinaa.
Syntyvää kuvaa verrataan tekstiin enkoodaamalla sekä kuva että teksti vertailukelpoiseen muotoon, ja ohjataan näiden eron perusteella latenttia kuvaa kohti parempaa vastaavuutta tekstin kanssa (kts. kirjan kappale Kieli kuvia ohjaamaan, kirjan s. 87 – 89). Kohinaskedulerin tehtävänä on säätää kohinan määrää juuri sopivasti, ja juuri sen tehtäväksi jää hallita kuinka kierrosten määrää vähennetään poistamalla kerralla enemmän kohinaa.
Tässä mallissa kuva edelleen kehittyy pikselikuvana, jolloin vähitellen vaimeneva kohina useimmiten näkyy miellyttävänä jälkenä keskeneräisessä kuvassa (kts. kirjan s. 99). Pikselikuvan käsittely U-netilla vaatii kuitenkin paljon muistia mikä taas käytännössä asettaa rajat kuvakoolle.
Voimme myös enkoodata kuvan kompressoituun muotoon samaan tapaan kuin VQGANissa (kirjan s. 81 – 83), niin että kuva jaetaan vaikkapa 8×8 px palasiin jotka esitetään numeromuotoon enkoodattuna.
Menetelmää jossa diffuusio tapahtuu enkoodatussa kutsutaan latentiksi diffuusioksi. Pikselikuvan (esim. 512×512×3 px) sijaan diffuusio tapahtuu nyt koodatulle kuvalle (esim. 64×64×4) eli huomattavasti pienemmässä koossa. Pitää kuitenkin ottaa huomioon myös, että nyt tarvitsemme dekooderin jolla saamme käyttökelpoisen kuvan. Enkooderinkin tarvitsisimme, jos käyttäisimme tekstiohjaukseen samaa tekniikkaa kuin edellä, eli vertaisimme syntyvää kuvaa tekstiin enkoodaamalla kummatkin vertailukelpoiseen muotoon.
Tekstiohjaus voidaan myös integroida osaksi diffuusioverkkoa, ja näin juuri mm. Stablediffusionissa tehdään, jolloin enkooderia ei tarvita. Enkoodattu teksti syötetään diffuusioverkolla ja kuvan ohjaus kohti tekstiä tapahtuu suoraan osana diffuusiota. Jos taas halutaan lähteä tietystä kuvasta, tarvitaan toki enkooderi jolla lähtökuva aluksi saadaan enkoodattuun muotoon (kuvassa Z).

Menetelmä on tehokas ja toteutus on kompakti, mutta varjopuolena on että tekstiohjaukseen ei voida käyttää valmiita verkkoja (CLIP), vaan diffuusioverkko pitää kouluttaa hallitsemaan diffuusion lisäksi myös tekstin ja kuvan vertailu. Kun lähes kaikki oleellinen toiminnallisuus on näin integroitu diffuusioverkon sisään, siihen on ulkopuolelta vaikea vaikuttaa, tässä kun ei enää ole ulkoista virheen perusteella tapahtuvaa ohjausta johon voisi lisätä omia lisätekijöitä kuvaa ohjaamaan. Vaikuttaa myös, että Stablediffusionin valmiiksi koulutettu diffuusioverkko ei ole niin monipuolinen kuin erillinen CLIP-pohjainen ohjaus. Sillä on helppo saada aikaan upeata kuvaa, mutta vaikeampi päästä vähän erikoisemmille alueille, mikä viittaa siihen että kouluttaminen on tehty suppeammalla aineistolla kuin alkuperäisen CLIP:in kohdalla.
Näkymiä tällä hetkellä
Kirjani lopussa kannoin huolta kuvasynteesin kivettymisestä sosiaalisen median tapaan mammuttiluokan suljetuiksi palveluiksi, jotka tuottavat käyttäjille onnistumisen kokemuksia ja joita käyttäjät ruokkivat omalla kuvamateriaalillaan. Stablediffusion on avoimella ratkaisullaan aika lailla kirkastanut näkymiä. Se ei ole kiinteä palvelu, vaan koostuu avoimen lisenssin ohjelmakirjastosta ja valmiiksi koulutetuista verkoista, joiden pohjalta voidaan kehittää erilaisia sovelluksia. Vaikka itselläni on epäilyksiä siitä onko sen teknikka taiteelliseen käyttöön kuitenkaan paras ratkaisu, niin sen ympärille on jo nyt kehittynyt hyvin mielenkiintoisia laajennuksia, kuten mahdollisuus pienellä vaivalla kouluttaa kuvien avulla uusia käsitteitä, vaikkapa laajentaa systeemin ymmärtämää kieltä omilla tyylillisillä käsitteillä.
Hyvälaatuisen kuvasynteesin leviäminen hyvin nopeasti laajaan tietoisuuteen on toisaalta nostattanut rajuakin vastarintaa varsinkin digitaalitaiteen piirissä. Ehkä ymmärrettävin huoli liittyy siihen kuinka helposti nimettyjen taiteilijoiden teosten tyyliä voidaan matkia. On vaadittu että verkkojen kouluttaminen teoskuvilla ja taiteilijoiden nimellä on kiellettävä tai enintään sallittava taiteilijan luvalla. Toisaalta nämä kriitikot eivät välttämättä täysin ymmärrä kuinka neuroverkot ja tekoäly toimivat. Itse näen että yleiskäyttöisen kuvaa hahmottavan tekniikan kouluttaminen millä hyvänsä julkisesti esillä olevalla kuvalla on verrattavissa siihen kuinka ihmisen visuaalinen hahmotus ja taju kehittyvät.
Matkiminen on toki toinen juttu, eikä pitkälle menevä matkiminen ole ennenkään ollut hyväksyttävää taiteen piirissä. Ehkä pitäisi erityisesti kiinnittää huomiota siihen, ettei tyylin matkijoita palkita vaan rohkaistaan ennemmin kehittelemään jotakin omaa.