



Edellisessä osassa näimme kuinka yksittäinen neuroverkon solu käsittelee numeerista tietoa ja kuinka näistä soluista voidaan koota kerroksia ja näistä monikerroksisia neuroverkkoja. Katsotaan seuraavaksi miten neuroverkolla voidaan käsitellä kuvia.
Mustavalkoinen kuva voidaan esittää kaksiulotteisena taulukkona, jossa kuvat pikselit on esitetty numeerisesti, esim. lukuina nollasta yhteen, jossa nolla vastaa mustaa ja yksi kirkkaan valkoista. Toinen yleisesti käytetty esitystapa on tallettaa pikselit kokonaislukuina 0..255, tässäkin nolla vastaa mustaa.
Otetaan sitten keinotekoinen neurosolu, johon syötetään yksi pikseli ja kaikki sen viereiset kahdeksan pikseliä.
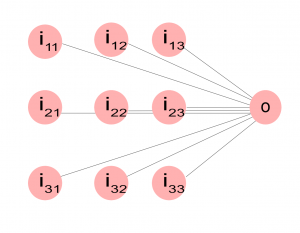
Tällainen solu voidaan opettaa havaitsemaan yksinkertaisia vierekkäisten pisteiden muodostamia kuvioita. Jos vielä ajattellaan että solua liu’utetaan kuvan päällä, voidaan näitä havaintoja tehdä koko kuvan alueella. Matemaattisesti puhutaan konvoluutiosta, jota on ennen neuroverkkojakin sovellettu kuvankäsittelyssä esim. kuvan sumentamiseen, tarkentamiseen ja reunojen havaitsemiseen. Perinteisessä konvoluutiossa liikkuvan ikkunan painokertoimet on asetettu ennalta halutun käyttötarkoituksen mukaan, neuroverkossa taas solut oppivat itse painokertoimet koulutusaineiston perusteella.
Tämmöistä kaksiulotteista solua ja varsinkin sen painokertoimia kutsutaan kerneliksi. Kerneliä ei kuitenkaan käytännössä liu’uteta kuvan päällä, vaan solua monistetaan tarvittava määrä niin että lopputulos on sama kuin jos kernel liukuisi kuvan päällä. Muistia kuluu enemmän, mutta toiminta saadaan nopeammaksi kun voidaan hyödyntää rinnakkaista laskentaa.
Ylläolevassa kuvassa on 3×3 kernel, mutta muunkinkokoisia kerneleitä käytetään, yleensä ei kuitenkaan kovin isoja. Voisi toki ajatella, että isompi kernel pystyy tunnistamaan kuvasta mutkikkaampia piirteitä, mutta käytännössä toimii paljon paremmin että käytetään pientä kerneliä, 3×3 tai 4×4, ja kootaan näistä konvoluutiokerroksia joita sitten kasataan useita päällekkäin. Tällaisessa verkossa alemmat kerrokset havaitsevat yksinkertaisia piirteitä, esim. värejä ja reunoja, ylemmät sitten viivoja ja käyriä, edelleen ylemmät erilaisia muotoja ja hahmoja, kunnes pystytään tunnistamaan kuvista olentoja ja esineitä. Kukin kerros sisältää vielä lukuisia rinnakkaisia osakerroksia (channels, feature maps) joista kukin reagoi eri piirteisiin.
Tässä olen tutkinut kahden eri kerroksen reagointia valokuvaan. Vasemmanpuolinen osakerros näyttää reagoivan vaakaviivoihin, oikeapuoleinen johonkin mutkikkaampaan kokonaisuuteen.


Tässä sitten kaavakuva verkosta, jolla pystytään tunnistamaan ja luokittelemaan kuvan sisältöä.
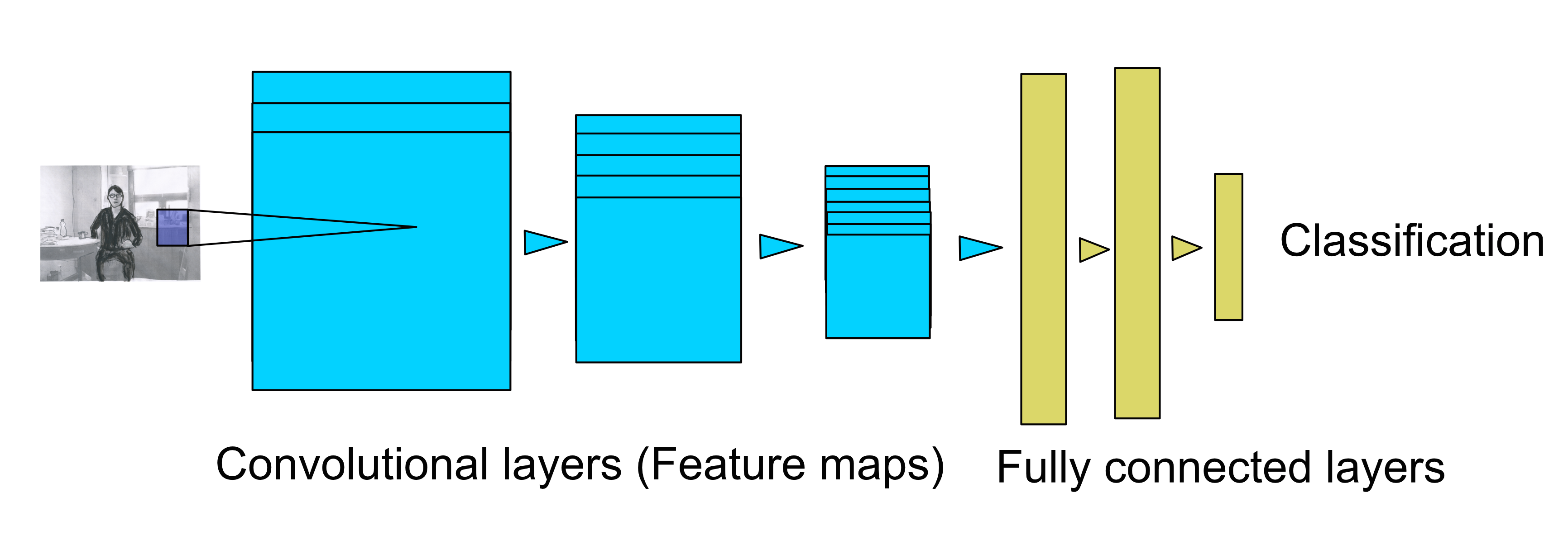
Vasemmalla on kuva josta lähdetään liikkeelle, värikuvan tapauksessa esim. 3 väriä x 256 x 256 matriisi. Tästä mennään konvoluutiokerroksella muotoon vaikkapa 64 osakerrosta x 256 x 256, tämän perässä vielä yksi tai useampi konvoluutiokerros samoilla mitoilla. Sitten pudotetaan kokoa puoleen ja samalla lisätään osakerrosten määrää: 128 osakerrosta x 128 x 128 ja jatketaan. Ja taas koko puoleen mutta osakerroksia lisää: 256 osakerrosta x 64 x 64. Sitä mukaan kuin abstraktiotaso kasvaa, havaitaan isompia kokonaisuuksia ja siksi tilallisen tarkkuuden tarve vähenee: on tärkeämpää että kukin solu kattaa suuremman osan kuvasta.
Viimeisen (sinisen) konvoluutiokerroksen jälkeen muutetaan kaksiulotteinen lähtö yksiulotteiseksi vektoriksi ja syötetään se muutaman tavallisen neuroverkkokerroksen läpi jotta lopulta saadaan arvio siitä mitä verkon mukaan näkyy. Nämä kerrokset käytännössä tekevät päätelmiä alempien kerrosten havaitsemien piirteiden perusteella, nyt ei siis enää käsitellä kuvaa vaan tehdään loogisia tai matemaattisia johtopäätöksiä. Oikeapuoleisimman verkon lähdöstä saadaan esimerkiksi 1000 todennäköisyyttä, yksi kutakin havaittavissa olevaa kohdetta kohti.
Kokeillaan sitten käytännössä. Nyt tarvitaan edelleen Torch, joten jos et asentanut sitä viime kerralla, niin se pitää asentaa ensimmäisenä. Torchin lisäksi tarvitaan nn, joka toteuttaa neuroverkkotoiminnallisuuden. Se asennetaan luarocks-komennolla, joka tulee Torchin asennuksen mukana: kirjoita komentorivillä ”luarocks install nn”. Tarvitset myös muita paketteja: ”luarocks install image” kuvien lukemiseksi ohjelmaan, ja ”luarocks install loadcaffe” valmiiksi koulutetun neuroverkon lataamiseksi ohjelmaan.
Ohjelman, neuroverkon ja muut tarvittavat tiedostot saat näillä komennoilla:
# haetaan ohjelma
wget liipetti.net/htoyryla/share/predict.lua
# haetaan valmiiksi koulutettu paikkoja ymmärtävä neuroverkko
wget http://places2.csail.mit.edu/models_places365/vgg16_places365.caffemodel
wget https://raw.githubusercontent.com/metalbubble/places365/master/deploy_vgg16_places365.prototxt
# haetaan lista jolla tulokset muutetaan selväkielisiksi
wget https://raw.githubusercontent.com/metalbubble/places365/master/categories_places365.txt
# haetaan kaksi esimerkkikuvaa wget liipetti.net/htoyryla/share/viktualien.jpg
wget https://github.com/jcjohnson/neural-style/raw/master/examples/inputs/tubingen.jpg
Nyt, jos kaikki meni oikein, voit kokeilla komentoa:
th predict.lua viktualien.jpg
Ohjelma tulostaa ensin tietoa neuroverkon lataamisesta ja rakenteesta, mutta lopuksi saadaan tulokset:
0.36294424533844 /b/beer_hall 54
0.20446613430977 /c/cafeteria 75
0.13476124405861 /f/food_court 148
0.063512079417706 /p/pub/indoor 274
Nyt voit kokeilla kuvalla tubingen.jpg ja sen jälkeen omilla kuvillasi. Voit myös tutustua itse ohjelmakoodiin, se ei ole mitenkään mutkikas.
require 'torch'
require 'nn'
require 'image'
require 'loadcaffe'
-- kuvan esiprosessointi
-- mm. vähennetään keskiarvo jotta saadaan pikseliarvot samalle alueelle kuin koulutettaessa
function preprocess(img)
local mean_pixel = torch.DoubleTensor({103.939, 116.779, 123.68})
local perm = torch.LongTensor{3, 2, 1}
img = img:index(1, perm):mul(256.0)
mean_pixel = mean_pixel:view(3, 1, 1):expandAs(img)
img:add(-1, mean_pixel)
return img
end
-- haetaan kategorioiden nimet
-- jotta tulokset voidaan näyttää selväkielisenä
f = io.open("categories_places365.txt")
labels = {}
for line in f:lines() do
table.insert(labels, line)
end
local imgf = "tubingen.jpg"
if arg[1] then
imgf = arg[1]
end
-- ladataan kuva muistiin ja skaalataan siihen kokoon jolla verkko on koulutettu
content_image = image.load(imgf, 3)
content_image = image.scale(content_image, 224, 224, 'bilinear')
content_image_caffe = preprocess(content_image):float()
img = content_image_caffe:clone():float()
-- ladataan valmis neuroverkko muistiin
cnn = loadcaffe.load("deploy_vgg16_places365.prototxt", "vgg16_places365.caffemodel", "nn"):float()
-- lisätään verkon perään SoftMax-kerros
prob = nn.SoftMax():float()
cnn:add(prob)
-- sitten vain kuva sisään verkkoon ja katsotaan mitä saadaan ulos
y = cnn:forward(img)
-- käydään tulokset yksitellen läpi
-- ja tulostetaan luokat joiden todennäköisyys ylittää 0.05
for i=1, 365 do
if y[i] > 0.05 then
print(y[i], labels[i])
end
end