



I have, in many of my posts, described my experiments using and mis-using neural-style. Some of my experiments can be rather hard to understand in detail unless the reader has a basic understanding how neural-style works. So this post will try to bridge that gap, without going into the mathematical or technical detail.
For those who have not followed through all previous posts, neural-style is a piece of software, developed by jcjohnson, which can create images that copy contents from one image while imitating the style of another. The principles behind this process were described in a scientific paper by Leon Gatys et. al., published in August 2015.
A convolutional neural network
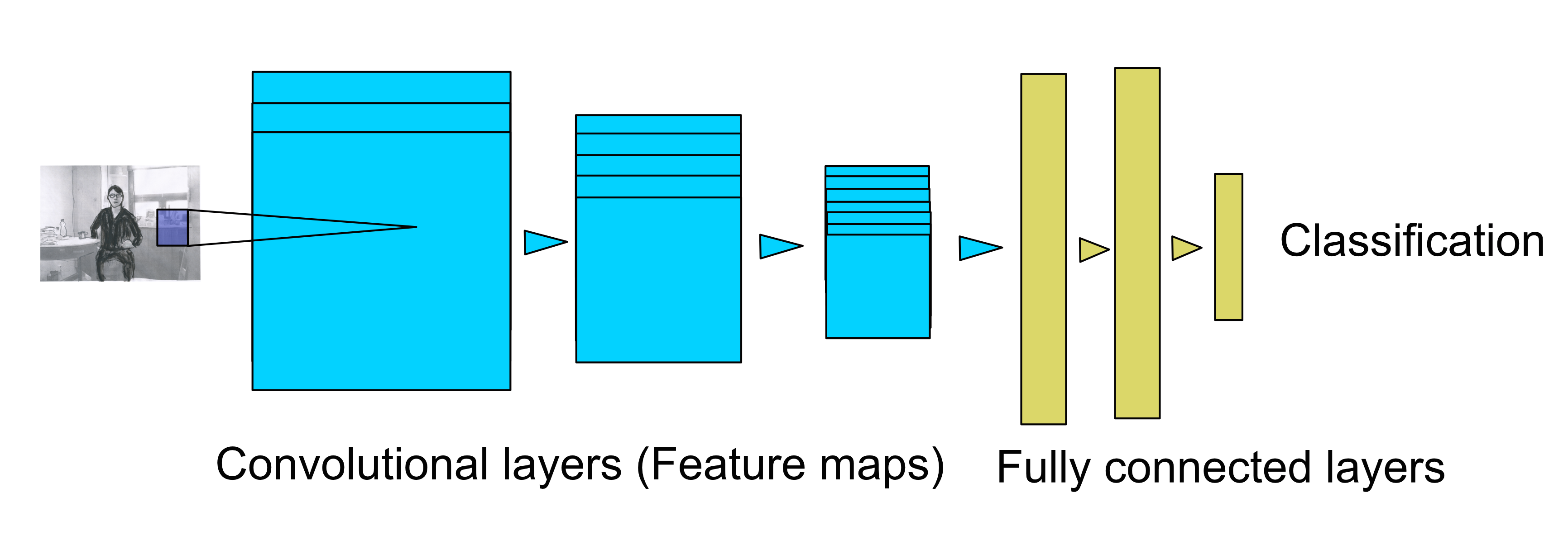
The core of neural-style is a convolutional neural network which has been trained to classify images, meaning that they can recognize objects in images describe the contents by a number of labels (such as “dog”, “house”, “car”, “tree”).
A small convolutional neural network (“convnet”) might look like this. Here, we have three convolutional layers, each of which consists of number of feature maps. The first convolutional layer scans the original image, using a small window called kernel. The kernel size is small, typically 7×7 pixels or 3×3 pixels. Eac feature map gets its values when the moving kernel calculates a weighted average of the pixels inside the kernel window. But where do the weights of the kernel come from? The convnet has learned them on its own during the training phase. In a well-trained convnet, each feature map responds to some essential feature, from lines and shapes in the lower layers to more complex features in the higher layers. The lower layers can typically have 16 feature maps of 256×256 pixels each, and moving to the upper layers, the the number of feature maps grows while the size decreases (e.g. 512 feature maps of 64×64 pixels each).
The feature maps correspond to the layout of input image, highlighting where in the original a particular feature is found. A particular map might respond to horizontal lines, as shown in the following image in which the contents of a feature map are show together with the original image.

The feature maps on higher layers respond to more specific features, like in the following image.

Note also, that all the weights that define how the feature maps react to inputs are automatically set in the training process. The training of a neural network consists of feeding a large amount of images to the network and adjusting the weights slightly towards giving the correct classifications.
All the convlayers can be thought of as a feature extractor. The uppermost convlayer contains the most abstract feature maps in the layer stack. On top of it, a few fully connected layers will then manage the feature classification, outputting the labels corresponding to what the network thinks it is seeing in the image. While the convlayers are like images and base their output on examining their input through the kernel windows, looking at the neighboring pixels only, the fully connected layers are one-dimensional, and each output is determined as a function of all inputs.
And now to neural-style
While it is possible to construct neural networks that output images, the typical convnets described above do nothing of the sort. They take in a image and output a classification. Still, neural-style uses a well-trained convnet model to its advantage to produce fine images combining the desired content and style.
This is achieved by using the welltrained model to measure the content and the style. The process is roughly as follows:
- feed the content image into the model and store the output from selected content layers as the content target
- feed the style image into the model and store a style representation from the output of the selected style layers as the style target
- create a new image initialized by noise
- feed this image into the model and make the same measurements as with the content and style images
- calculate the difference with regard to both content and style targets, respectively
- adjust the new image slightly, looking for a minimum of the content and style differences
- continue the process of adjusting and measuring the new image until we are happy with the results or a certain number iterations has been passed
It is interesting to note that the process of finetuning the new image is actually very similar to training a new neural network, and makes use of same procedures in looking for the minimum difference (usually called “loss”). So, in a way, we are training a new image to become as close to the content and style as possible, using the neural model as a tool for measuring the loss.
Where does this take us?
Now that we understand the basics how the convnet works and how neural-style uses it in the creation of new images, we can start to see what is at stake when choosing the layers for content and style in neural-style. The lower layers see simple features but have more spatial accuracy, the higher ones see complex features with less spatial accuracy. Of course, it is still unclear what features each model actually detects in all its layers, but that too can be studied experimentally, for instance producing images such as the two examples above. But that is a different story already.
We can also see now that neural-style only makes use of the feature extractor part of a neural model. The fully connected layers, so essential for classification, the original application of these models, is not used at all. There are two reasons for this: the information of these layers is too abstract and these layers totally ignore the spatial, two-dimensional layout of the images. If you start wondering what would happen if neural-style used these layers, have a look at my previous posts starting at Controlling image content with FC layers.
The fact that neural-style has no use for the fully connected layers has also implications that are not so obvious. For instance, if we want to start training our own neural models, it is easiest to start by taking an existing, already trained model and finetune it using our own image dataset. This is by far the fastest and easiest way to create a model which responds to a customized image dataset. The fine-tuning process, however, mainly modifies the fully connected layers, which as we know are not used in neural-style. But the issue of training one’s own model is already a different story.