



Tähän astisissa harjoituksissa olemme luoneet pikselikuvan, mitanneet sen samankaltaisuutta tavoitteeseen, ja ohjanneet tämän poikkeaman avulla kuvaa kohti tavoitetta. Kuva on koko ajan ollut pikselimuotoinen RGB-kuva, olemme siis ohjanneet suoraan kuvan pikseleitä. Tässä harjoituksessa kuva syntyy aivan toisella tavalla, niinkin erikoisella ettei se ole mitenkään kovin yleinen. Kun aloin tehdä näitä harjoituksia maaliskuussa 2021, tämä oli kuitenkin uusinta uutta, ja sen verran omaa luokkaansa, että sopii hyvin vastapainoksi sille että muutamme kuva pikseleitä suoraan.
Pikselien sijaan meillä on funktio, joka antaa koordinaattien perusteella pikselien arvot. Kuulostaa varmaan villiltä, oli matemaattinen funktion käsite tuttu tai ei. Voidaan ajatella, että meillä on musta laatikko. jonne voimme antaa pikselin koordinaatit (paikat kuvassa) ja saamme sieltä pikselin RGB-arvot. Vielä hurjempaa on, että funktio ei edes tiedä mitään pikseleistä. Se on jatkuva, eli saamme sieltä pikselien arvot myös pikselien välillä. Kuva ei ole sidottu tiettyyn resoluutioon, periaatteessa voisimme saada kuvan sieltä millä hyvänsä resoluutiolla.
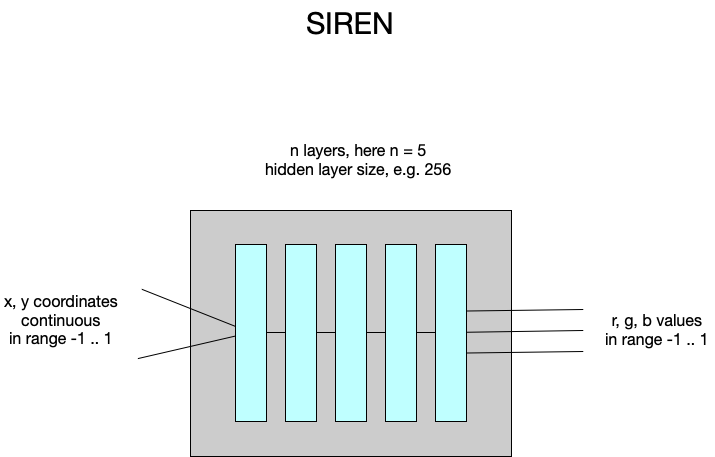
SIREN toteuttaa tällaisen funktion neuroverkon avulla; käytännössä se on neuroverkko joka koostuu kerroksista ja joka opetetaan yhdellä ainoalla kuvalla. Koordinaatit annetaan liukulukuina välillä -1 … 1, jolloin ääripäät vastaavat kuvan reunoja ja (0,0) kuva keskipistettä. Pikselit löytyvät, tai löydetään, sieltä väliltä. Samaten pikselin RGB-arvot saadaan välillä -1 … 1 missä -1 vastaa mustaa ja 1 täyttä väriä.
Kuinka me sitten saamme kuvan sieltä ulos, puhumattakaan siitä miten tuo on koulutettavissa? Teemme yksinkertaisesti wrapperin, ohjelman joka toimii ikäänkuin kääreenä SIREN:ille, käy kaikki pikselit läpi muuttamalla koordinaattien arvoja sopivin välein, ja tallettaa saadut arvot pikselikuvaan. Itse asiassa, koska neuroverkot yleensä tehdään käsittelemään kokonainen erä kerrallaan, voimme tehdä tensorin, jossa on kaikkien pikselien koordinaatit, ja näin saada kerralla valmis pikselikuva ulos. Juuri näin tämän harjoituksen SIREN-toteutus toimii.
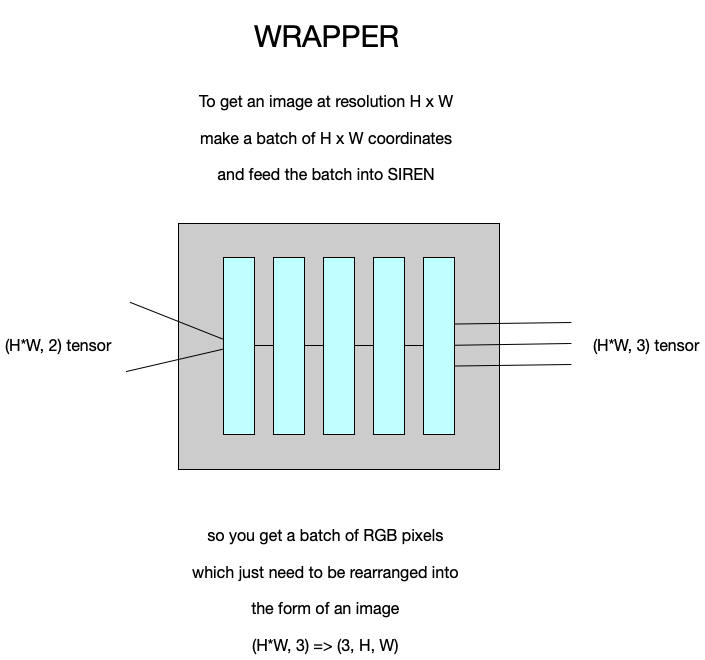
Kuinka sitten sovitamme tämmöisen kummajaisen siihen mitä olemme tekemässä? Olemme tekemässä kuvaa, meidän pitää korvata pikselimatriisi imgG SIREN:illä ja wrapperillä, siitä saamme pikselimatriisin ja voimme jatkaa kuten tähänkin asti.
Käydään sitten itse koodin kimppuun. SIREN löytyy pip-pakettina, asentuu komennolla
pip install siren-pytorch
ja itse ohjelmassa otamme em. paketista käyttöön Sirenin ja sen wrapperin
from siren_pytorch import SirenNet, SirenWrapper
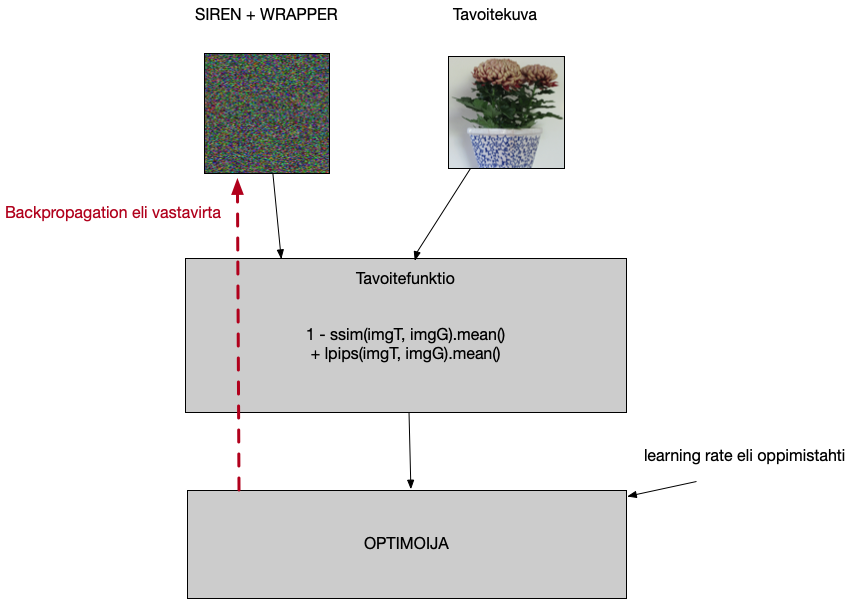
Katsotaan tällä kertaa myös kaikki parametrit tässä. Tarvitsemme kuvatiedoston, koulutustahdin, koulutuskierrosten määrän, lopullisen kuvakoon, nimen jolla tallennetaan. Voimme valita näytetäänkö kuvaa myös näytöllä ikkunassa. Tavoitefunktiossa käytämme nyt SSIM:iä ja pikselikohtaista virhettä (MSE).
# use command line parameters
parser = argparse.ArgumentParser()
# define params and their types with defaults if needed
parser.add_argument('--image', type=str, default="test.png", help='path to image')
parser.add_argument('--lr', type=float, default=0.0005, help='learning rate')
parser.add_argument('--niter', type=int, default=150, help='number of iterations')
parser.add_argument('--imageSize', type=int, default=256, help='image size')
parser.add_argument('--name', type=str, default="harj4", help='basename for storing images')
parser.add_argument('--show', action="store_true", help='show image in a window')
parser.add_argument('--ssim', type=float, default=1, help='ssim weight')
parser.add_argument('--mse', type=float, default=1, help='mse weight')
# get params into opt object, so we can access them like opt.image
opt = parser.parse_args()
Luodaan sitten itse SIREN ja sille wrapper, aluksi kiinteillä asetuksilla. Voimme myöhemmin muuttaa koodia niin että niitäkin voi antaa komentorivilitä.
# NOW LET'S SET UP SIREN
siren = SirenNet(
dim_in = 2, # input dimension, ex. 2d coor
dim_hidden = 256, # hidden dimension
dim_out = 3, # output dimension, ex. rgb value
num_layers = 6, # number of layers
w0_initial = 30., # different signals may require different omega_0 in the first layer - this is a hyperparameter
final_activation = nn.Tanh()
)
wrapper = SirenWrapper(
siren,
image_width = opt.imageSize,
image_height = opt.imageSize
)
Ennen kuin alamme optimoida, pitää vielä valita mitä tarkalleen optimoidaan, mikä on sitä minkä haluamme muuttuvan koulutuksen myötä. Ja jotta hommassa olisi mieltä, muutoksen täytyy kohdistua johonkin sellaiseen minkä muuttaminen pystyy viemään kuvaa lähemmäs tavoitetta. Aiemmissa harjoituksissa annoimme itse pikselien muuttua. Nyt pitäisi saada SIREN oppimaan se funktio, joka vastaa haluttua kuvaa.
SIREN on neuroverkko, joka on nimenomaan suunniteltu oppimaan tällainen funktio. Ja ensimmäinen neuroverkko jonka otamme käyttöön tässä kurssissa. Emme nyt sukella sen sisuskaluihin, riittää että se koostuu kerroksista, ja kukin kerros käsittää suuren määrä opittavissa olevia parametreja, enimmäkseen painokertoimia joita käytetään laskennassa. Ja meidän ei nyt edes tarvitse tietää enempää näistä parametreistä, Siren on aito torch.nn -moduli, siinä on rajapinta jonka kautta löydämme ne parametrit ja voimme luoda optimoijan seuraavasti
# Now we want to optimize parameters inside SIREN to produce the image optimizer = torch.optim.Adam(siren.parameters(), opt.lr)
Itse koulutussilmukka kokonaisuudessaan on tässä. Aluksi nollamme optimoijan gradientin, mikä tarkoittaa yksinkertaisesti sitä että edellisen kierroksen aikana havaittu poikkeama unohdetaan. Haetaan kuva Sirenin wrapperilta. Lasketaan virhe, sekä SSIM:in että pikselivirheen avulla. Sitten valutetaan virhe takaperin, minkä seurauksena konepellin alla on ns. gradientti, tieto siitä kuinka paljon kukin verkon painokerroin on pielessä ja mihin suuntaan. Optimoija sitten säätää niitä hivenen oikeaan suuntaan, näin verkko oppii.
for i in range(0, niter):
optimizer.zero_grad()
# get image from Siren
imgout = wrapper()
# calculate loss
loss = opt.ssim * (1 - ssim(imgT.unsqueeze(0), imgout))
# in addition to SSIM, we now also use pixel loss as measured by MSE loss
# MSE = mean square error (google for more)
if opt.mse > 0:
loss += opt.mse * F.mse_loss(imgT.unsqueeze(0), imgout)
# run backwards to find gradient (how to change imgG to make loss smaller)
loss.backward()
# run optimizer to change imgT
optimizer.step()
# print loss to show how we are doing
print(i, loss.item())
# save image
if (i < 10) or (i % 10 == 0):
save_image(imgout, opt.name+str(i)+".jpg", normalize=True)
# show on screen
if opt.show:
show_on_screen(imgout[0], opt.name)
Kun tätä kokeilee ajaa, huomaa heti eron suoran pikselikuvan tekoon. Alussakaan kuva ei ole ns. lumisadetta, kohinaa, vaan jonkinlaista väritäplästöä. Ja kun sireenin antaa oppia, niin alkaahan sieltä kuva löytyä.



